
नमस्ते दोस्तों, आज के इस ब्लॉग में हम जानेंगे नेचुरल लैंग्वेज प्रोसेसिंग के बारे में, जैसे कि नेचुरल लैंग्वेज प्रोसेसिंग क्या है (What is Natural Language Processing in Hindi) यह किस प्रकार कार्य करता है और क्यों यह इतना महत्वपूर्ण हैं इत्यादि।
दोस्तों, आपने कभी न कभी गूगल या किसी अन्य टूल से कोई प्रश्न तो अवश्य ही किया होगा, परन्तु क्या आपने कभी यह सोचा है आखिर ये सभी टूल तो प्रोग्रामिंग भाषाओ से बने होते है तो हमारी अलग-अलग मानवीय भाषाओ को कैसे समझ लेते हैं।
इसका जवाब है दोस्तों Natural Language Processing (NLP) की सहायता से, तो आइये Natural Language Processing Kya Hai इसे और अधिक गहराई से समझते हैं।
Natural language processing Kya Hai – NLP in Hindi

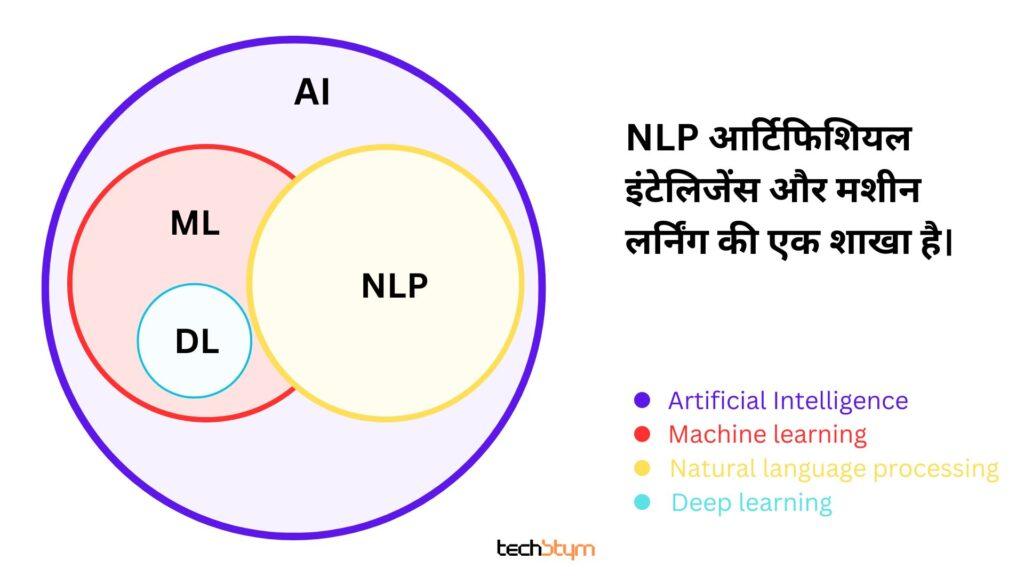
नेचुरल लैंग्वेज प्रोसेसिंग (NLP) आर्टिफीसियल इंटेलिजेंस और मशीन लर्निंग की एक शाखा है। जो कम्प्यूटर्स को मानवीय भाषा पढ़ने, समझने, और उसका अर्थ निकालने में सक्षम बनाती हैं।
चाहे वह भाषा बोली या लिखी गयी हो, यह तकनीक मानवीय भाषा में दिए गए इनपुट को समझने, उसका अर्थ निकालने और विश्लेषण करने में सक्षम होती हैं।
इसके लिए यह मशीन लर्निंग अल्गोरिथ्म्स का उपयोग करती है। इसका उपयोग करके यह तकनीक मानवीय भाषा में प्राप्त इनपुट को उस भाषा (code) में परिवर्तित करती है, जिसे कंप्यूटर आसानी से समझ सकता है।
आसान शब्दों में कहे तो NLP कम्प्यूटर्स को मानवीय भाषा समझने और उसका विश्लेषण करने में सक्षम बनाती हैं।
नेचुरल लैंग्वेज प्रोसेसिंग का उपयोग उन साड़ी टूल्स, डिवाइस और उपकरणों में होता है, जिनका उपयोग करने के लिए मानवो को किसी प्राकृतिक भाषा का उपयोग करना पड़ता है।
उदाहरण के लिए,
- Google Translation
- Google Assistant
- ChatGPT
- Alexa
- Midjourney
Introduction to Natural Language Processing in Hindi
नेचुरल लैंग्वेज प्रोसेसिंग यानी NLP Kya Hai, इसे तो आपलोग समझ गए होंगे। परन्तु क्या आप जानते हैं? आखिर यह तकनीक इतना महत्वपूर्ण क्यों हैं। चलिए जानते है की NLP क्यों महत्वपूर्ण हैं (why is NLP important in Hindi)
Natural Language Processing (NLP) क्यों महत्पूर्ण है?
नेचुरल लैंग्वेज प्रोसेसिंग कम्प्यूटर्स और मानवो के बीच प्राकृतिक भाषा में संवाद करने का एकमात्र माध्यम हैं। जिसकी सहयता से कम्प्यूटर्स मानवो की प्राकृतिक भाषाओ को समझते है और समझकर प्रतिक्रिया दे पाते हैं।
NLP की सहायता से कोई भी उपकरण और सॉफ्टवेयर जैसे google, Youtube, Gemini, Chatgpt और Robots इत्यादि। हमारे द्वारा पूछे गए प्रश्नो को समझते है, कि हम उनसे क्या जानकारी प्राप्त करना चाहते है और पूछे गए प्रश्न के आधार पर उसका उत्तर भी हमारी भाषा में दे पाते है।
यदि यह तकनीक न हो दोस्तों तो हम कभी मोबाइल या कोई अन्य डिवाइस का उपयोग हमारी भाषाओ का प्रयोग करके नहीं कर पाएंगे, हम सभी मोबाइल आदि का उपयोग करने के लिए Computer Languages सीखना पड़ेगा।
इससे आप अंदाज़ा लगा सकते है की आखिर Natural Language Processing इतना महत्वपूर्ण क्यों हैं।
तो नेचुरल लैंग्वेज प्रोसेसिंग क्या है (What is Natural Language Processing in Hindi) और क्यों यह इतना महत्वपूर्ण हैं इसे तो आप समझ गए होंगे। परन्तु क्या आप जानते है आखिर यह हमारी भाषाओ को प्रोसेस करता कैसे है?
इसका कार्य थोड़ा जटिल और मजेदार है तो आइये इसे भी समझते हैं।
Natural language processing (NLP) कैसे कार्य करता है?
जिस प्रकार मानवो के पास किसी भाषा को सीखने, समझने के लिए उसका मस्तिष्क होता है, उसी प्रकार कम्प्यूटर्स के पास किसी भाषा को पढ़ने, सीखने और समझने के लिए प्रोग्राम्स होते हैं।
इन्ही प्रोग्राम्स की सहायता से नेचुरल लैंग्वेज प्रोसेसिंग तकनीक हमारी प्राकृतिक भाषाओ को पढ़ते और उनका सही-सही अर्थ निकालते हैं।
भाषा प्रोसेसिंग के दौरान ये प्रोग्राम्स मानवीय प्राकृतिक भाषाओ को कोड के रूप में परिवर्तित कर देती हैं। जिससे कंप्यूटर आसानी से हमारी बातो का मतलब क्या हैं, हम उनसे क्या कहना चाहते हैं, इसका पता लगा लेते हैं।
ये प्रोग्राम्स कम्प्यूटेशनल भाषाविज्ञान (computational linguistics), मशीन लर्निंग (machine learning) और गहन शिक्षण मॉडल (deep learning model) से मिलकर बनी होती है।
1. कम्प्यूटेशनल भाषाविज्ञान (computational linguistics):
ये कम्प्यूटर्स के साथ मानव भाषा मॉडल को समझने और निर्माण करने का विज्ञान है। कम्प्यूटेशनल भाषाविज्ञान की मुख्यतः दो विधिया है, वाक्यविन्यास (syntax) और अर्थ विश्लेषण (semantic analysis)
जिनका उपयोग करके यह कम्प्यूटर्स को संवादी मानव भाषा को समझने में सक्षम बनाते है। आमतौर पर इस्तेमाल किये जाने वाले टूल्स जैसे language translator, text-to-speech synthesizers, और speech recognition software इत्यादि, इसी कम्प्यूटेशनल भाषाविज्ञान पर आधारित होते है।
2. मशीन लर्निंग (machine learning)
मशीन लर्निंग एक ऐसी तकनीक है जो कम्प्यूटर्स को किसी वाक्य की पहचान की सटीकता को बढ़ाने के लिए सैंपल डाटा के आधार पर प्रशिक्षित करती हैं। चूँकि मानवीय भाषा में व्यंग्य, रूपक, वाक्य संरचना में विविधता, व्याकरण और उपयोग अपवाद जैसी कई विशेषताएं शामिल हैं जिन्हें सीखने में मनुष्य को वर्षों लग जाते हैं।
इसलिए प्रोग्रामर्स शुरू से ही NLP को इन विशेषताओं को पहचानने और इसका सटीक अर्थ निकालने के लिए मशीन लर्निंग तकनीक का उपयोग करते हैं।
3. गहन शिक्षण मॉडल (deep learning)
गहन शिक्षण मॉडल मशीन लर्निंग का एक महत्वपूर्ण क्षेत्र हैं जो कम्प्यूटर्स को मनुष्य की तरह सिखने और सोचने में सक्षम बनाती हैं। इसमें न्यूरल नेटवर्क भी शामिल होता हैं जिसमे मानव मस्तिष्क के सामान संरचित डेटा प्रोसेसिंग करने की क्षमता होती हैं।
Natural language processing के प्रोग्राम मुख्यतः दो चरणों में मानवीय प्राकृतिक भाषा को प्रोसेस करते हैं। Data pre-processing और Algorithms developments
Data Preprocessing:
Data Preprocessing नेचुरल लैंग्वेज प्रोसेसिंग का वह भाग है जिसमे पाठ को साफ़ और ऐसे तैयार किया जाता है की वह अगले विश्लेषण के लिए तैयार हो सके।
मतलब पाठ में उपस्तिथ कई अवांछित तत्वों को हटाया, जोड़ा और बदला जाता है। ताकि प्रोसेसिंग के अगले चरणों में computers आसानी से उस पाठ का सही-सही अर्थ सफलतापूर्वक कम सब्दो में प्राप्त कर सके।
Data Preprocessing आमतौर पर कई चरणों में होता है, जो निचे निम्नलिखित हैं:
Tokenization
Word tokenization हिंदी में इसे “शब्द विभाजन” भी कहते है, इसका कार्य किसी वाक्य को छोटी-छोटी इकाइयों में बाँटना हैं। उदहारण
| Original Text | Tokenized Words |
| मैं एक छात्र हूं। | [मैं, एक, छात्र, हूं] |
| भारत एक बड़ा देश है। | [भारत, एक, बड़ा, देश, है] |
| यह किताब बहुत दिलचस्प है। | [यह, किताब, बहुत, दिलचस्प, है] |
| मेरा प्यारा गाँव शांति से भरपूर है। | [मेरा, प्यारा, गाँव, शांति, से, भरपूर, है] |
| हिन्दी मेरी मातृभाषा है। | [हिन्दी, मेरी, मातृभाषा, है] |
Stop word removal
इसका उपयोग किसी पाठ मे दोहराव वाले शब्द और वैसे शब्दों को हटाने के लिए होता है जिसे हटाने पर उस पाठ का मतलब नहीं बदलता हो। उदाहरण
| (मूल वाक्य) | (स्टॉप शब्द हटाने के बाद वाक्य) | (हटाए गए स्टॉप शब्द) |
| यह एक अच्छा दिन है। | अच्छा दिन | यह, एक, है |
| मैं घर जा रहा हूँ। | घर जा रहा | मैं, हूँ |
| आप क्या कर रहे हैं? | क्या कर | आप, रहे, हैं |
| यह किताब बहुत दिलचस्प है। | किताब दिलचस्प | यह, बहुत, है |
Lemmatization और Stemming
यह दोनों तकनिको का उपयोग, शब्दों को उनके मूल स्वरूप मे लाने के लिए किया जाता हैं। जहाँ lemmatization शब्द को उसके व्यावहारिक रूप से उसके सही मूल रूप तक लाता है। वही stemming किसी शब्द के शुरू या अंत के कुछ अक्षरों को हटाकर उस शब्द को उसके मूल स्वरूप तक लाता हैं। उदाहरण
| (मूल शब्द) | Lemmatized Word (मूल रूप) | Stemmed Word (स्तम्भ) |
| पढ़ रहा हूँ (reading) | पढ़ता है (reads) | पढ़ (read) |
| लिखती है (writes) | लिखता है (writes) | लिख (write) |
| सुंदर है (beautiful) | सुंदर है (beautiful) | सुंद (beautiful) |
| छोटा सा (small) | छोटा है (small) | छोट (small) |
Algorithms developments
Data Preprocessing के बाद, प्राप्त डेटा को प्रोसेस करने के लिए algorithms को विकशीत किया गया है। वैसे तो कई algorithms विकशीत हो चुके है, लेकिन मुख्यतः इन दोनों का प्रयोग किया जाता है।
- Machine learning-based system: इसका कार्य दिए गए प्रशिक्षण डाटा के आधार पर कार्यों को करना, सीखना और अधिक डाटा संसाधित होने पर खुद को उसके अनुसार अनुकूल बनाना है, और machine learning, deep learning और neural network का उपयोग करके natural language processing algorithms के नियमों को बेहतर बनाते रहना भी है।
- Rule-based system: इसको इस प्रकार डिजाइन किया है की यह भाषाई नियमों का प्रयोग सावधानीपूर्वक करते है, इस प्रणाली का उपयोग सबसे पहले natural language processing के विकाश मे किया जाता था और आज भी इसका प्रयोग किया जाता है।
मुझे उम्मीद है की आप अब तक नेचुरल लैंग्वेज प्रोसेसिंग क्या है (What Is Natural Language Processing in Hindi) और यह कैसे कार्य करता है, इसे समझ गए होंगे।
अब आइये जानते है Natural Language Processing (NLP) के कुछ प्रमुख तकनीकों को जिसका उपयोग करके यह हमारी भाषाओ को प्रोसेस करते हैं।
Natural Language Processing (NLP) की तकनीके
नेचुरल लैंग्वेज प्रोसेसिंग मानवीय प्राकृतिक भाषा को सिखने, उसका सटीक अर्थ निकालने के लिए कई तकनीकों का उपयोग करती हैं। जिनमे प्रमुख है – वाक्यविन्यास विश्लेषण (syntax analysis) और शब्दार्थ विश्लेषण (semantic analysis)
वाक्यविन्यास विश्लेषण (Syntax analysis)
वाक्यविन्यास विश्लेषण (Syntax analysis) नेचुरल लैंग्वेज प्रोसेसिंग को किसी वाक्य में उपस्तिथ व्याकरण जैसे विशेषताओं को पहचानने और उस वाक्य का सटीक अर्थ निकालने में सक्षम बनाता हैं।
इसके लिए यह कई तकनीके जैसे रूपात्मक विभाजन (morphological segmentation), वाक्य विभाजन (sentence segmentation), भाग-प्रकार अंकन (part-of-speech tagging) का उपयोग करती हैं।
रूपात्मक विभाजन (Morphological Segmentation)
इसे हिंदी में ‘शब्द काटना’ भी कहा जाता है, यह शब्दों को उनके छोटे अर्थपूर्ण इकाइयों में तोड़ने की प्रक्रिया है, जिन्हें morphemes कहा जाता है। ये morphemes किसी शब्द के सबसे छोटे अर्थपूर्ण हिस्से होते हैं, जिनसे मिलकर उस शब्द का अर्थ बनता है। चलिए इसे भी उदाहरण से समझते है।
| शब्द | शब्द विभाजन |
| किताबों | 1. किताब; 2. ओ (बहुवचन प्रत्यय) |
| पढ़ाया | 1. पढ़ (पढ़ना, verb root) 2. या (गतिकलिक क्रिया प्रत्यय) |
| चलाकर | 1. चल ( चलना, verb root) 2. अ (तत्पुरुष समास का संधि स्वर, 3. कर (संज्ञा बनाने वाला प्रत्यय) |
| सोच रहे | 1. सोच (सोचना) 2. रहे (वर्तमान प्रतिशील क्रिया प्रत्यय,) |
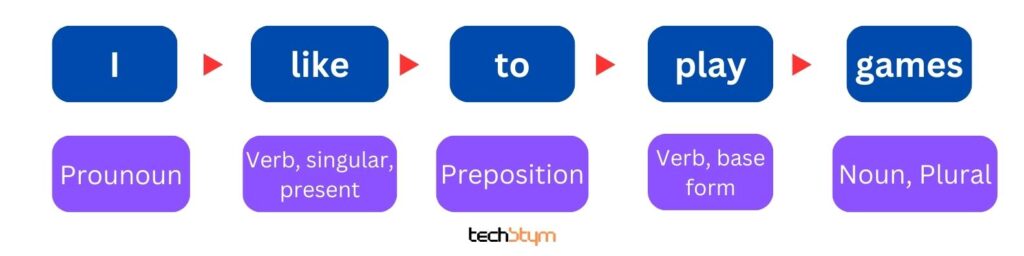
भाग-प्रकार अंकन (Part-of-speech tagging)
इसका उपयोग वाक्यों मे उपस्थित व्याकरण का विश्लेषण करने के लिए किया जाता है।
आइए इसे उदाहरण से समझते है, मान लेते है की natural language processing को एक वाक्य “I like to play games” दिया गया।
वाक्य विभाजन (Sentence segmentation)
वाक्य विभाजन (sentence segmentation) एक ऐसी प्रक्रिया है, जिसमे किसी पाठ को प्रोसेसिंग के समय छोटे-छोटे अर्थपूर्ण वाक्यों के रूप मे तोड़ा जाता है। उदाहरण :-
| वाक्य | विभाजन |
| मुझे बाजार जाना है, कुछ सब्जियां और फल लेने हैं। रास्ते मे अगर मिले तो दूध, ब्रेड और अंडे भी ले लूँगा। | [मुझे बाजार जाना है।] [कुछ सब्जियां और फल लेने है।] [रास्ते मे अगर मिले तो दूध, ब्रेड और अंडे भी ले लूँगा।] |
शब्दार्थ विश्लेषण (Semantic analysis)
शब्दार्थ विश्लेषण (semantic analysis) नेचुरल लैंग्वेज प्रोसेसिंग NLP को किसी वाकया में उपस्थित भावनाए, प्रशंग, इमोशन, और उसके इरादे को समझने में सक्षम बनता हैं।
जिसके लिए यह मुख्य रूप से दो तकनीकों जैसे शब्द बोध असंबद्धता (word sense disambiguation) और नामित इकाई पहचान (named entity recognition) का उपयोग करता हैं। आइये इन्हे जानते हैं –
शब्द बोध असंबद्धता (Word sense disambiguation)
शब्द बोध असम्बद्धत्ता एक ऐसी तकनीक है जो कम्प्यूटर्स को किसी वाक्य में उपस्तिथ कोई एक शब्द के कई संभावित अर्थो में से कौन सा अर्थ उस वाक्य के लिए उचित है यह समझने में मदद करता हैं।
आइये इसे भी एक उदहारण के माध्यम से समझते हैं।
“Bank” शब्द का अर्थ “नदी का किनारा,” या ” वित्तीय संस्थान,” दोनों ही होते है।
शब्द बोध असंबद्धता यानि Word sense disambiguation यह निर्धारित करने मे मदद करता है कि किस वाक्य मे “बैंक”का कौनस अर्थ लागू होगा।
नामित इकाई पहचान (Named entity recognition)
नामित इकाई पहचान (named entity recognition) एक ऐसी तकनीक है, जो किसी वाक्य में विभन्न श्रेणियों को नामित इकाइयों को पहचान कर उन्हें लेबल चिन्हित करती हैं। इन इकाइयों में नाम, स्थान,संगठन, तिथियां, मात्राएँ, प्रतिशत, मुद्राएं, आदि शामिल होते हैं।
उदहारण के लिए, एक वाक्य है “ताजमहल को आगरा में 1632 में बनाया गया था।” इस वाक्य में निम्नलिखित नामित इकाइयां हो सकती हैं: जैसे “नाम: ताजमहल,” “स्थान: आगरा,” “तिथि: 1632,”
इससे कंप्यूटर को पाठ के अर्थ को बेहतर ढंग से समझने और विभिन्न कार्यों जैसे कि सूचना पुनर्प्राप्ति, प्रश्न उत्तर, और मशीन अनुवाद में मदद मिलती है।
प्राकृतिक भाषा निर्माण (Natural language generation)
प्राकृतिक भाषा निर्माण (natural language generation) नेचुरल लैंग्वेज प्रोसेसिंग सॉफ्टवेयर को मानवीय प्राकृतिक भाषा में संवाद करने में सक्षम बनाता हैं। इसे “स्वाभाविक भाषा रचना” भी कहा जाता हैं। इसका उपयोग ChatGPT और Bard जैसे generative AI टूल्स करते हैं।
Natural language processing (NLP) का क्या उपयोग है।

{kind=link}
नेचुरल लैंग्वेज प्रोसेसिंग NLP का उपयोग आज हर टेक्नोलॉजी से जुड़ी क्षेत्रो में किया जाता हैं। मुख्य रूप से इसका उपयोग संवाद और बातचीत, जानकारी प्रसंस्करण और विश्लेषण, कंटेंट क्रिएशन और रचनात्मकता जैसे कार्यो के लिए किया जाता हैं।
संवाद और बातचीत:
- चैटबॉट्स और वर्चुअल असिस्टेंट: इसका उपयोग आपके साथ बातचीत करने के लिए इस्तेमाल किए जा रहे हैं। ये आपके सवालों को समझकर उसी हिसाब से जवाब देने की कोशिश करते हैं।
- मशीन अनुवाद: Natural language processing अब हिंदी और दूसरी भाषाओं के बीच अनुवाद को ज़्यादा सटीक और स्वाभाविक बना रहा है। इससे आप किसी भी भाषा को आसानी से अपनी मनचाही भाषा में अनुवाद कर सकते हैं।
- टेक्स्ट-टू-स्पीच और स्पीच-टू-टेक्स्ट: इसका प्रयोग किसी लिखित वाक्य को स्पीच मे बदलने और स्पीच को लिखित वाक्य मे बदलने के लिए किया जाता है।
- भाव विश्लेषण: इससे NLP लिखे टेक्स्ट को समझ सकता है कि लेखक क्या महसूस कर रहा है या उसकी राय क्या है। इसका इस्तेमाल market research, social media monitoring, और customer satisfaction को बढ़ाने में किया जा सकता है।
जानकारी प्रसंस्करण और विश्लेषण:
- सर्च इंजन: NLP की मदद से सर्च इंजन आपके सवाल को समझते हैं और आपको सबसे ज़्यादा रिलेवेंट नतीजे दिखाते हैं।
- टेक्स्ट सारांश: NLP किसी भी टेक्स्ट के मुख्य बिंदुओं को निकाल सकता है, जिससे समय और मेहनत की बचत होती है।
- दस्तावेज़ वर्गीकरण: NLP किसी भी दस्तावेज़ को उसके कंटेंट के हिसाब से श्रेणीबद्ध कर सकता है। उदाहरण के लिए, वो किसी ईमेल को स्पैम या गैर-स्पैम में बांट सकता है।
- डाटा विश्लेषण: इसका प्रयोग रियल टाइम ट्रेंड्स निकालने के लिए किया जाता है। इसका इस्तेमाल बाज़ार में क्या चल रहा है ये समझने के लिए, वैज्ञानिक शोध में, और सामाजिक विश्लेषण में किया जा सकता है।
कंटेंट क्रिएशन और रचनात्मकता:
- मशीन लेखन: NLP को large language model (LLM) पर ट्रेन किया जाता है, जिससे वो कविता, कहानी, स्क्रिप्ट, गीत, और यहां तक कि कोड भी लिख सकता है।
- संवाद निर्माण: NLP चैटबॉट्स और वर्चुअल असिस्टेंट के लिए ज़्यादा आकर्षक बातचीत बना सकता है।
- व्यक्तिगत कंटेंट निर्माण: NLP आपकी रुचि और पसंद के हिसाब से कंटेंट तैयार कर सकता है।
- व्याकरण और वर्तनी सुधार: NLP लिखे हुए text में व्याकरण और वर्तनी की गलतियों को सुधार सकता है।
Natural Language Processing (NLP) का इतिहास
प्राकृतिक भाषा प्रसंस्करण (NLP) की शुरुआत जब लोग सोचने लगे कि कैसे हमारे कंप्यूटर हमारी भाषा को समझ सकते हैं। 1940 में यह विचार आया। फिर 1948 में, लंदन के एक कॉलेज में लोगों ने पहली बार NLP का परिचय किया।
फिर 1950 के दशक में, कंप्यूटर साइंस और भाषा विज्ञान के बीच एक बड़ा टकराव आया। एक महत्वपूर्ण व्यक्ति chomsky ने उस समय Generative Grammar का प्रस्ताव दिया था।
फिर 1968 में, भाषा विज्ञानी Charles J. Fillmore ने कुछ नया बनाया, जिसे हम case grammar कहते हैं। यह एक तरह की भाषा है जिससे कंप्यूटर समझ सकता है कि किस तरह से शब्द और वाक्य का अर्थ हो सकता है।
1968 और 1970 के बीच, एक और बड़ा प्रोजेक्ट आया जिसे ‘SHRDLU’ कहा गया। इसे Terry Winograd ने बनाया था और यह कंप्यूटर को समझाने में मदद करता था, ताकि हम इससे बात कर सकें।
1980 के बाद, NLP में मशीन लर्निंग का इस्तेमाल किया। जिससे कंप्यूटरों को सिखने और सुधारने की क्षमता मिली।
इसके माध्यम से NLP बना और आगे बढ़ा, जिससे आज हम और अधिक आसानी से कंप्यूटर के साथ बातचीत कर सकते हैं।
निष्कर्ष:
मुझे पूरा विश्वास है की इस ब्लॉग को पढ़ने के बाद नेचुरल लैंग्वेज प्रोसेसिंग से सम्बंधित हर प्रकार की जानकारी जैसे: नेचुरल लैंग्वेज प्रोसेसिंग क्या है (What is Natural Language Processing in Hindi), क्यों महत्वपूर्ण है, यह कैसे कार्य करता है, इसका क्या उपयोग है, कैसे इसका निर्माण हुआ, इत्यादि आपको प्राप्त हो गयी होगी। यदि आपको इस ब्लॉग से कुछ नया सिखने को मिला हो, तो इसे अपने दोस्तों से साथ भी शेयर करे और किसी भी प्रकार की जानकारी NLP से सम्बंधित पूछना या देना चाहते हो कमेंट करे और ऐसे ही टेक्नोलॉजी से जुड़ी मजेदार कॉन्सेप्ट्स को समझना चाहते है तो हमे अवश्य फॉलो करते रहे।
Pingback: नहीं जानते, Machine learning क्या हैं? आओ हम बता देंगे।
Pingback: Deep Learning Kya Hai? पूरी जानकारी